Extraindo dados de PDF com Python
Recentemente um amigo chegou em mim perguntando como ele conseguiria fazer para extrair dados de um PDF de uma forma rápida (sem ser da forma tradicional de copiar e colar), já que teria que fazer a extração de dados de um montante de PDFs. Não consegui responder de primeira, mas sabia que conseguiria codar algo que poderia ajudá-lo, agora estou aqui escrevendo sobre meus resultados.
Bibliotecas
- glob: Listar arquivos com a mesma extensão
- PDFQuery: Para extrair as informações do PDF
- PrettyTable: Mostrar na tela em formato de tabela
Instalação das Bibliotecas
pip install pdfquery
pip install prettytable
Coletando dados por Cordenada
Esse será o PDF usado como exemplo, e iremos coletar CNPJ/CPF e CEP, censurei as informações pra não expor dados verdadeiros.

Para conseguir as cordenadas precisamos converter o PDF em um XML, assim obtendo uma árvore de elementos e com os elementos encontrar os itens com os seletores no mesmo estilo do JQuery.
from pdfquery import PDFQuery
def _pdf_to_xml(file: str, output: str) -> None:
pdf = PDFQuery(file)
pdf.load()
pdf.tree.write(output, pretty_print=True, encoding="utf-8")
return
if __name__ == "__main__":
print('* pdf to xml tree')
_pdf_to_xml('test.pdf', 'result.xml')
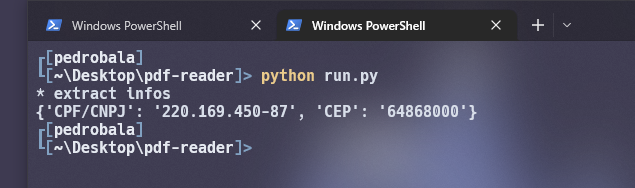
Proximo passo é abrir o arquivo XML gerado e encontrar os valores que queremos, no caso do exemplo abaixo procurei pelo valor do CPF (220…).
Você pode pensar na página pdf em termos de coordenadas XY, sendo o eixo X a largura da página e o Y a altura.
Usaremos o parâmetro bbox. Uma bbox consiste em quatro coordenadas: o X e Y do canto inferior esquerdo e o X e Y do canto superior direito.

Com a informação do bbox, fica fácil, usamo a função extract pra extrair os valores de dentro das box
- LTTextBoxHorizontal: Tag do XML
- in_bbox: Corresponde apenas aos elementos que se encaixam inteiramente na bbox fornecida.
- with_formatter: Define uma função de formatação padrão
from typing import Dict, Any
from pdfquery import PDFQuery
def _extract(pdf: PDFQuery) -> Dict[Any, Any]:
result = pdf.extract([
('with_formatter', 'text'),
('CPF/CNPJ', 'LTTextBoxHorizontal:in_bbox("14.4, 510.137, 76.979, 515.761")', lambda match: match.text()[10:]),
('CEP', 'LTTextBoxHorizontal:in_bbox("206.4, 567.931, 255.368, 575.699")', lambda match: match.text()[5:])
])
return result
if __name__ == "__main__":
print('* extract infos')
pdf = PDFQuery('test.pdf')
pdf.load()
result = _extract(pdf)
print(result)
E voilá, informações extraida com sucesso.
Extraindo uma lista de PDFs
Como o problema não era examente só extrair de um único PDF e sim de uma lista, então chegou a parte de automatizar completamente, usaremos o glob para listar os pdf de um certo diretório, gerar uma lista e extrair PDF por PDF.
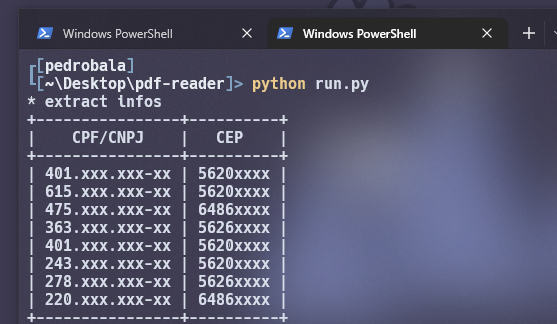
Para deixar algo melhor visivel vamos adicionar os dados a uma tabela usando PrettyTable
# Montando o Header da tabela
table = PrettyTable(['CPF/CNPJ', 'CEP'])
for file in glob("*.pdf"):
pdf = PDFQuery(file)
pdf.load()
result = _extract(pdf)
table.add_row([result['CPF/CNPJ'], result['CPF/CNPJ']])
As informação irão aparecer de forma tabelada, e finalizamos o script.
Conclusão
Existem várias outras maneiras de se fazer esse tipo de extração, como por exemplo usando OCR mas eu particularmente não fui atrás, essa me pareceu a mais simples.
Codando ao som de Biggie ft. Eazy-E & 2Pac - Write This Down
Referências
- https://github.com/jcushman/pdfquery